转载请注明出处:
总结下常用的排序算法,方便以后查阅。
常见排序算法:冒泡排序、选择排序、插入排序、壳(shell)排序、合并排序、快速排序、堆排序。
要选择合适的算法,需考虑的因素:执行时间、存储空间和编程工作。
1、选择排序
具有二次方程增长阶,近适用于小列表排序。
通过列表反复扫描,每次扫描选择一项,然后将这一项移动到列表中正确的位置。
选择排序总比较次数=(n-1)+(n-2)+(n-3)+...+3+2+1
=n(n-1)/2
n(n-1)/2是O(n^2)阶的级,所以选择排序是阶O(n^2)的算法。
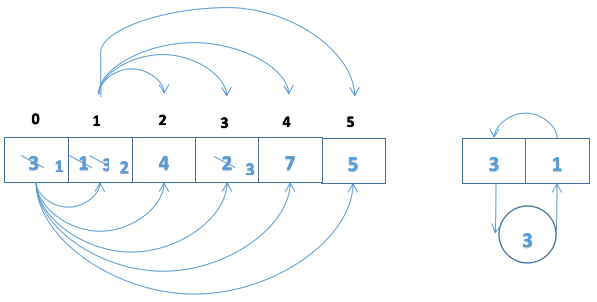
//外循环控制行(循环比较次数) for (int i = 0; i < arr.length-1; i++) { //内循环控制列,前后两个比较 for (int j = i+1; j < arr.length; j++) { if(arr[i]>arr[j]){ int temp=arr[i]; arr[i]=arr[j]; arr[j]=temp; } } } 2、冒泡算法
相邻两个元素进行比较,如果符合条件就换位。
冒泡排序总比较次数=(n-1)+(n-2)+(n-3)+...+3+2+1
=n(n-1)/2
n(n-1)/2是O(n^2)阶的级,所以冒泡排序是阶O(n^2)的算法。
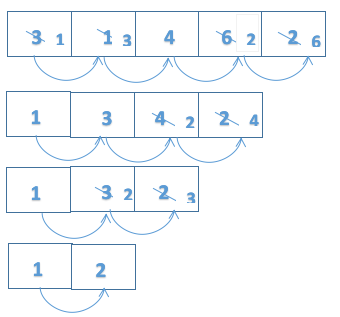
//最后一个元素不需要比较for (int i = 0; i < arr.length-1; i++) { //-i:让每次比较的元素减少;-1避免下标越界,即当j=4时,j+1就越界了 for (int j = 0; j < arr.length-i-1; j++) { if(arr[j]>arr[j+1]){ int temp=arr[j]; arr[j]=arr[j+1]; arr[j+1]=temp; } } } 3、快速排序
基本思想:
(1)先从数列中取出一个数作为基准数(一般取区间第一个数)
(2)区分过程,将比这个数大的数全放在它的右边,小于或等于它的数放到它的左边。
(3)再对各区间重复第二步,直到各区间只有一个数。
这里的例子我们用挖坑填数发来说明:
再对a[0-4]和a[6-9]这两个子区间重复上述步骤就可以了,先从后向前找,再从前向后找。
对挖坑填数进行总结:
1. i=l,j=r,将基准数挖出形成第一个坑a[i];
2. j--由后向前找比它小的数,找到后挖出此数,填前一个坑a[i]中;
3. i++由前向后找比它大的数,找到后也挖出次数填到前一个坑a[j]中。
4. 在重复执行2,3两步,直到i==j,将基准数填入a[i]中。
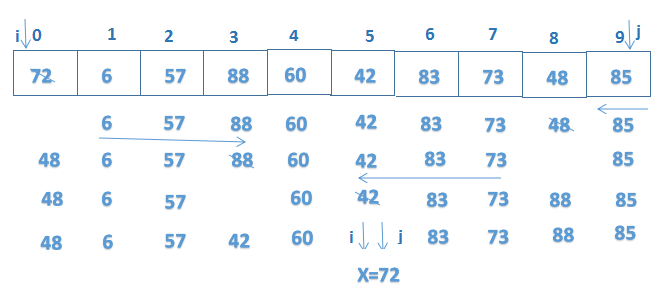
void quick_sort(int s[],int l,int r){ if(l =x){j--;}//从右向左找第一个小于x的数 if(i 4、插入排序
具有二次方程增长阶,仅用于小列表排序。
如果需要排序的列表几乎已经排序,则插入排序比冒泡排序和选择排序更有效率。
插入排序执行不同次数的比较,这取决于最初的元素分阶,当元素已经处于排序阶,则插入排序需要进行极少比较。

需将列表分为两个子列表,即排序和未排序。
排序列表 未排序列表
for (int i = 0; i < arr.length; i++) { //假设第一个元素放到了正确的位置上,这样仅需遍历1~n-1 int j=i; int target=arr[i]; while(j>0&&target 最佳用例效率:O(n),当列表已经被排序时,产生最佳用例。
最差用例效率:O(n^2),当列表反向顺序排列时,产生最差用例。
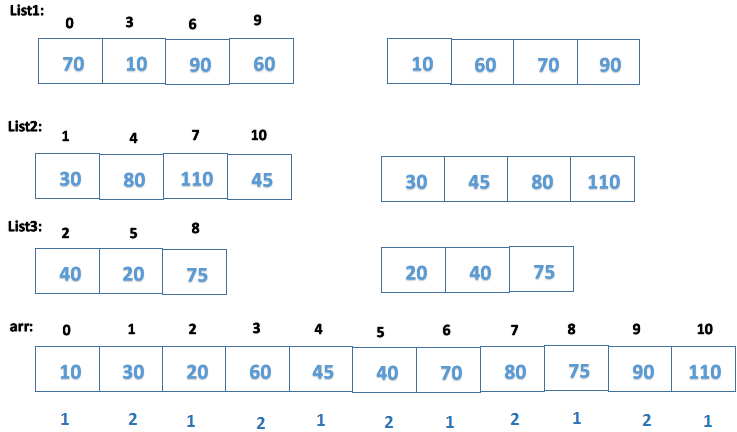
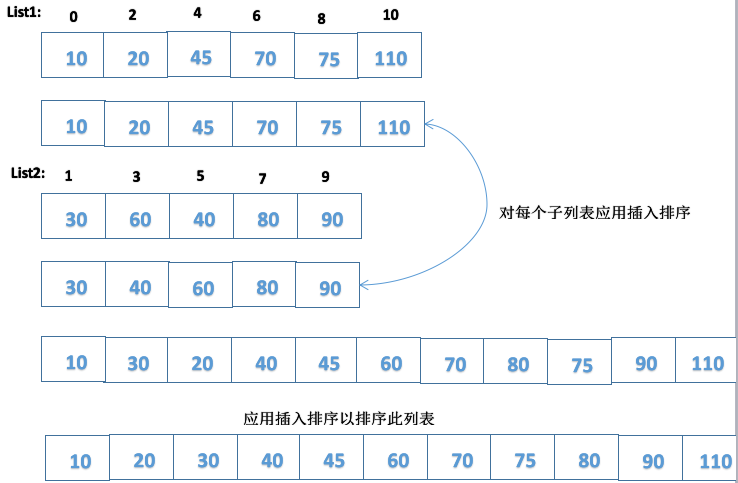
5.壳(Shell)排序
通过若干位置的距离形成多个子列表分隔元素并进行比较来改进插入排序算法。对每个子列表应用插入排序时元素朝着其正确的位置移动,减少了比较次数。

-------选择分隔组中元素的距离以形成多个子列表。(这里为3)
-------对每个子列表应用插入排序使元素朝着其正确的位置移动。
6.堆排序
堆排序与快速排序、归并排序一样都是时间复杂度为O(nlogn)的几种常见排序。
若将堆视为一个完全二叉树,则堆的含义为:完全二叉树中有非叶结点(ri)均不大于(后不小于)其左孩子的值(r(2)i),右孩子的值(r(2i+1))。
堆定义是:n个关键字序列k1,k2,k3,...kn称为堆,当且仅当该序列满足如下性质:
(1)ki<=k(2i)且ki<=k(2i+1)或
(2)ki>=k(2i)且ki>=k(2i+1) (1<=i<=[n/2])
即孩子结点>=双亲结点 或 孩子结点<=双亲结点
eg:{6,8,7,9,01,3,2,4,5}说明采用堆排序方法进行排序的过程。

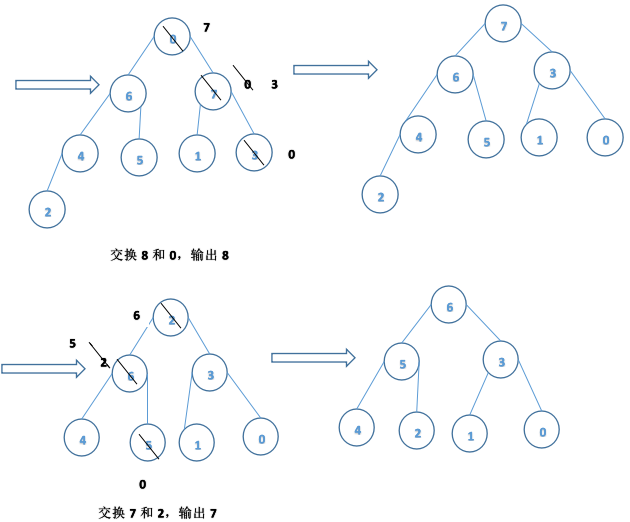
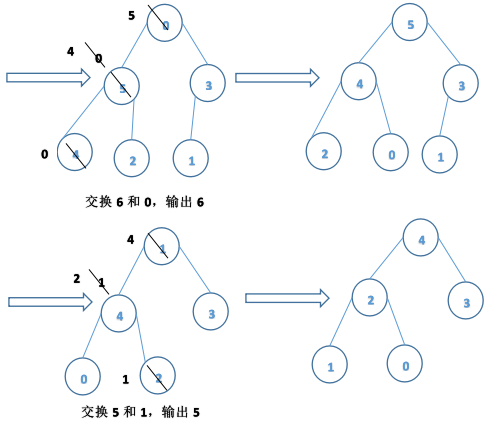

输出:9,8,7,6,5,4,3,2,1,0
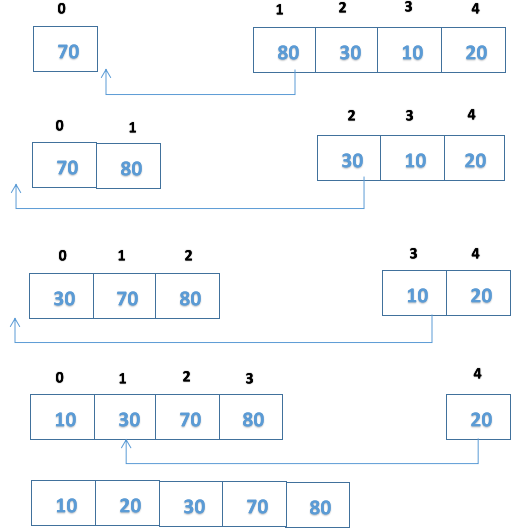
7.归并排序
多次将若干个已经排序好的有序表合并成一个有序表。直接将两个表合并的归并成为二路归并。
eg:{18,2,20,34,12,32,6,16}说明归并排序方法进行排序的过程。
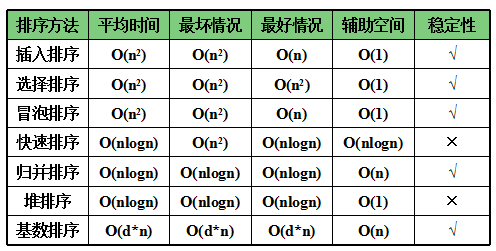
时间特性说明:
时间复杂度O(nlogn):快速、堆、归并排序。快速最快,在n较大时,归并较堆更快。
时间复杂度为O(n^2):插入、冒泡、选择排序。插入最常用,尤其基本有序时,选择记录移动次数最少。
当待排序记录有序时:插入和冒泡可达到O(n),快速蜕化到O(n^2).
选择、堆、归并排序的时间特性不随关键字分布而改变。
如果此文对您有帮助,微信打赏我一下吧~
